This week-end our production system had an “interesting” behavior/issue.
Symptoms
- music content metadata was not accessible for about 20 minutes : users cannot find music or see it in their playlists
Informations
- the issue was reported by a user
- the alert sent was not adequate and did not escalate
Background
We update our music metadata daily and deploy it using a blue-green deployment pattern. These metadata are deployed in containers in Kubernetes. The deployment script waits for the new deployment to be in a Ready state before switching traffic towards it.
Investigation
It was time to open Honeycomb and figure out what had happened. We had configured Honeycomb to collect our kubernetes state metrics so we were able to query these events:
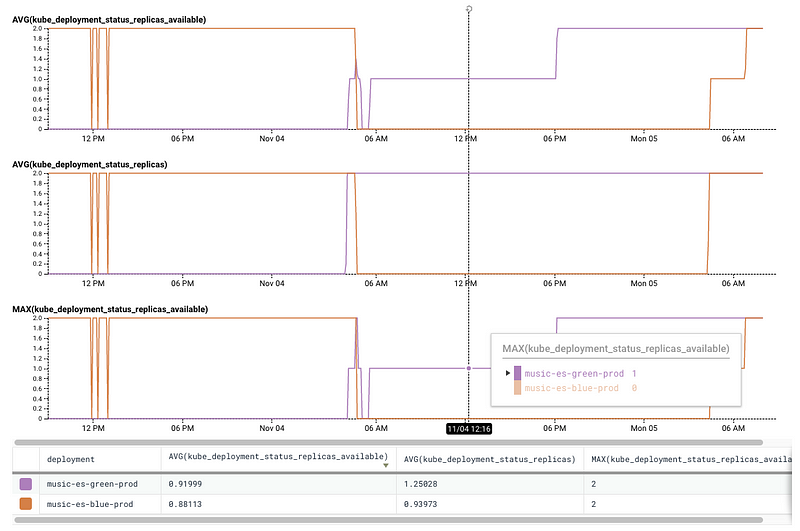
The first graph shows the ‘average’ “blue” traffic (orange line) goes from 2 to 0 replicas as expected, though “green” traffic is not completely succeeding in average number of ready replicas.
The second graph show the expected behavior of required replicas for both deployments with the overlapping period when the script is waiting for the new deployment pods to be ready.
The third graph shows the measured MAX number of ready replicas, which was used by the deployment script (it queries the current number from Kubernetes api): as soon as the blue deployment pods were ready, the traffic was switched to it. Except as the graph shows, the blue pods failed, leaving the service without any pod to serve music metadata. Later the deployment recovered and things went back to normal.
Conclusion
- we need an alert based on content returned
- the deployment script needs to make sure the new deployment is stabilized before sending traffic to it