Upgrading a Kubernetes cluster can be a problematic adventure even when using tools like kops.
Kops takes care of updating all the infrastructure code and apply the changes in a rolling fashion but it cannot resolve scheduling dead ends if you did not prepare your cluster before migration.
Our main friction point when upgrading Kubernetes, causing outages, has been our failure to prepare our cluster to allow it to rollout the update without downtime.
What happened?
While Kops was rolling out new updated nodes with the new version of Kubernetes, it got stuck waiting for evicted pods to be rescheduled on another Node. A quick kubectl describe pod revealed that no node within the availability zone required was available with enough resources to schedule the pod. Indeed this pod had requirements for a specific availability zone because of the persistent volume (EBS backed) that it relied upon.
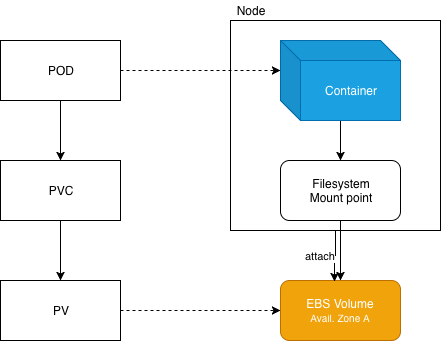 K8s resources vs Actual resources
K8s resources vs Actual resources
The cluster had minimal number of nodes (one per zone) and none was available in the desired zone.
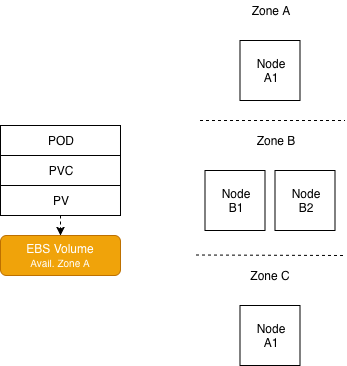 Where to schedule this pod?
Where to schedule this pod?
How to fix?
(Before starting the upgrade), we provisioned more node to make sure we had more than once per availability zone. This allowed the rescheduling of evicted pod to proceed normally. Once the upgrade finished, we reduced the number of nodes back.
Lessons learned
When we think about Kubernetes resources, it’s easy to forget about their concrete dependencies on actual hardware or services that have their own limitations (in our case the fact that an EBS volume is limited to its availability zone). Therefore moving resources around, for a migration for example, requires to plan and prepare the cluster to be able to accomplish a smooth upgrade.